学习门槛高
零基础入门难,大数据框架种类繁多,学习难度很大且耗费大量时间难以坚持下来

当前浏览器可能影响体验,请下载Google浏览器!
我们现在处在一个数据的海洋当中
有前途,更有“钱途”
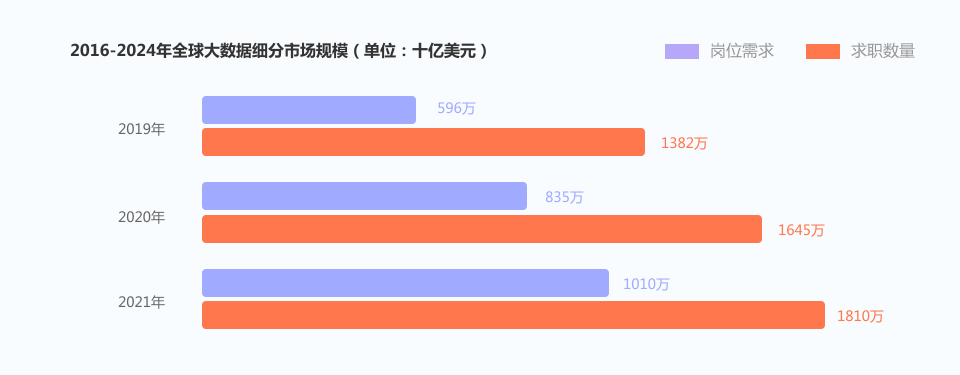
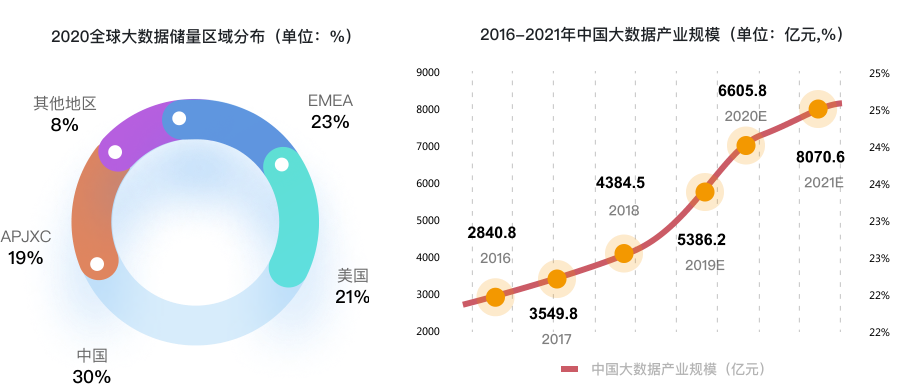
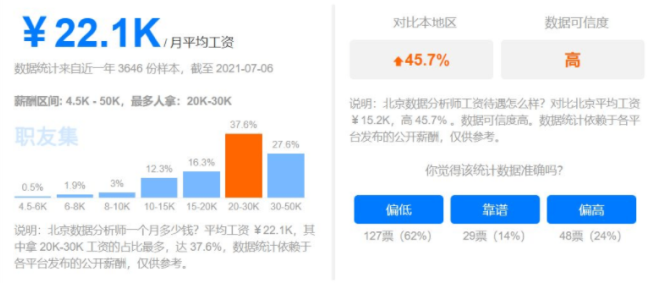
当今时代,大数据应用的价值已经展露在各行各业中,而大数据人才的供不应求也是目前大数据行业面临的一大困境。 2020年中国大数据行业的人才需求规模达到210万,2025年前大数据人才需求仍将保持30%-40% 的增速,需求总量在2000万人左右。 需求大,薪资待遇自然水涨船高。
有恒心者,事可成

希望转岗Hadoop开发工程师、Spark开发工程师、Flink开发工程师、大数据架构师、大数据全栈工程师等岗位

工作内容固定,想往大数据更深层次发展,期望跳槽涨薪

有Java基础、Python基础以及计算机等相关专业的本科生或者研究生

非计算机专业群体,迫切期待学习一项有前景、发展好、高薪的计算机技术

对大数据具备很高的兴趣爱好,希望从事相关行业或者自己创造相关产品
切记闭门造车,我在马士兵等你
零基础入门难,大数据框架种类繁多,学习难度很大且耗费大量时间难以坚持下来
缺少真实项目实战经验,面对实际业务一筹莫展,无法将实际问题转化为数据问题

架构层面经验缺乏,身边无行业大牛指导,提升缓慢,难以入行
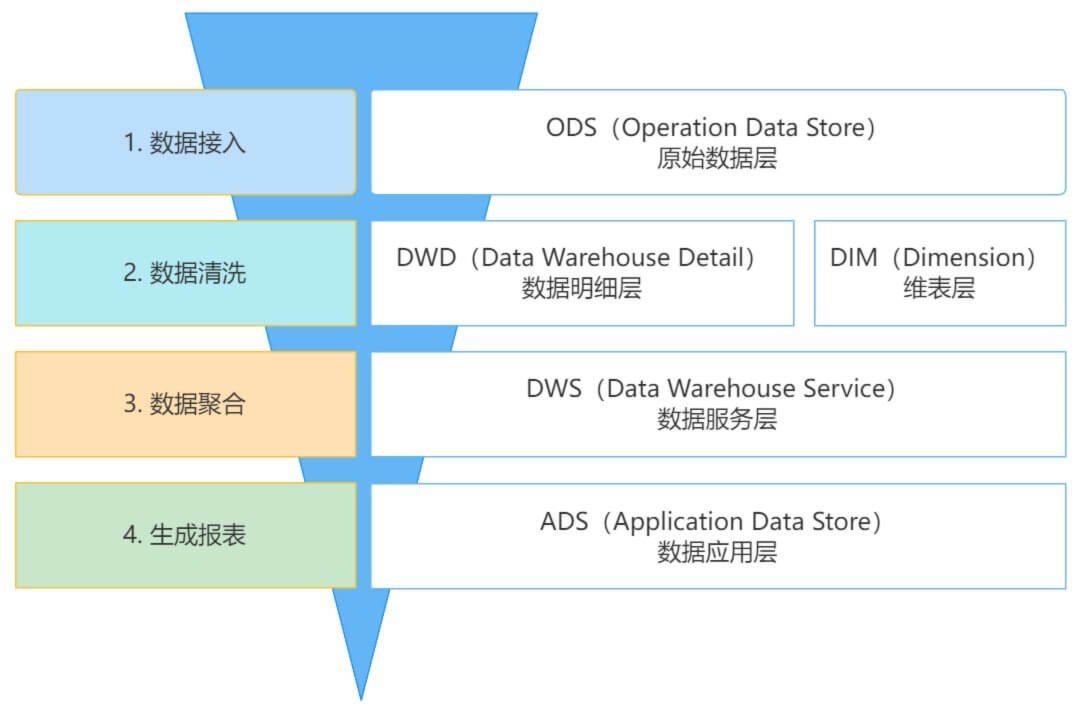
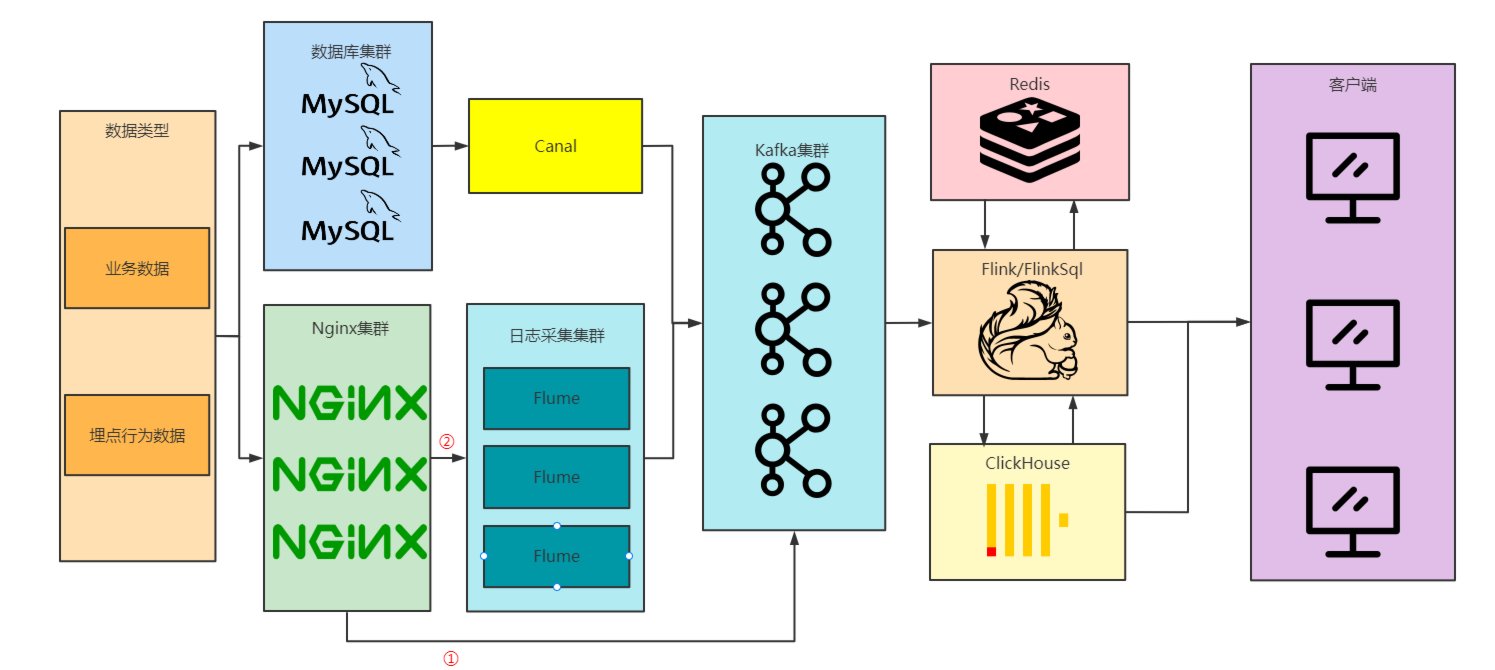
需要组合流式组件、存储系统、计算组件和可靠性、可扩展性及可运维性要求高
一个课程,理论+实战+面试,一次全搞定

本套课程包含了EB级架构设计架构底层技术体系、EB级架构设计数据分布式采集体系、EB级架构设计数据中间件技术体系、EB级架构设计数据存储技术体系、EB级架构设计数据处理技术体系、EB级架构设计OLAP生态体系、EB级架构设计稳健架构设计体系、EB级架构设计集群调度管理体系、EB级架构设计数据挖掘体系、EB级架构设计项目架构设计体系课程,包含了大数据技术体系全部内容
技术大牛带你学,企业需求实时接轨






让学员体系化、系统化掌握大数据全栈开发技能
技术大牛带你学,企业需求实时接轨
背景资料,学习计划,开发课程权限,短期规划等录入系统
对学员进行互动了解后做出针对学员的专属学习计划
学习计划分阶段按时完成作业及笔记,互动查漏补缺
根据学习计划中的阶段,对模块知识点进行考核,评估掌握度即时调整学习计划
个人原因,考核原因,学习中重新调整学习计划
是个问答系统,也是一个知识库,在学习的过程中,将成千上万的程序员连接起来
邀请分享或参与分享,同时还有BATJ大牛大咖
群内公告当日更新最新内推招聘信息,课参与内推机会,但需要提前完成简历辅导
找工作钱需要完成简历辅导,待批改通过后可投递,保持互动及时反馈
面试过程中如多次面试未果,面试阻力大,应及时互动,必要时反馈面试录音,提升成功率
提出内推及反馈就业喜报信息的学员备有一份薄礼

我们说了不算,学过的学员说了才算

虎****


海****

H****

康****

孙****